

RAG(検索拡張生成)とは?社内Wiki・規程を生成AIで使うための仕組みと実例

生成AIを業務で使おうとすると、必ず直面する課題があります。「社内の情報をAIにどう扱わせるか」という問題です。
ChatGPTをはじめとする生成AIは非常に便利ですが、社内Wiki・規程・FAQ・契約書といった自社固有の情報は基本的に知りません。公開情報をもとに学習しているため、「御社の就業規則では……」といった質問にはまったく対応できないのが現状です。
この課題を解決する仕組みとして注目されているのがRAG(検索拡張生成)です。
本記事では、RAGを最新技術の解説としてではなく、「社内情報をAIで使うための設計思想」として解説します。
RAG(検索拡張生成)とは
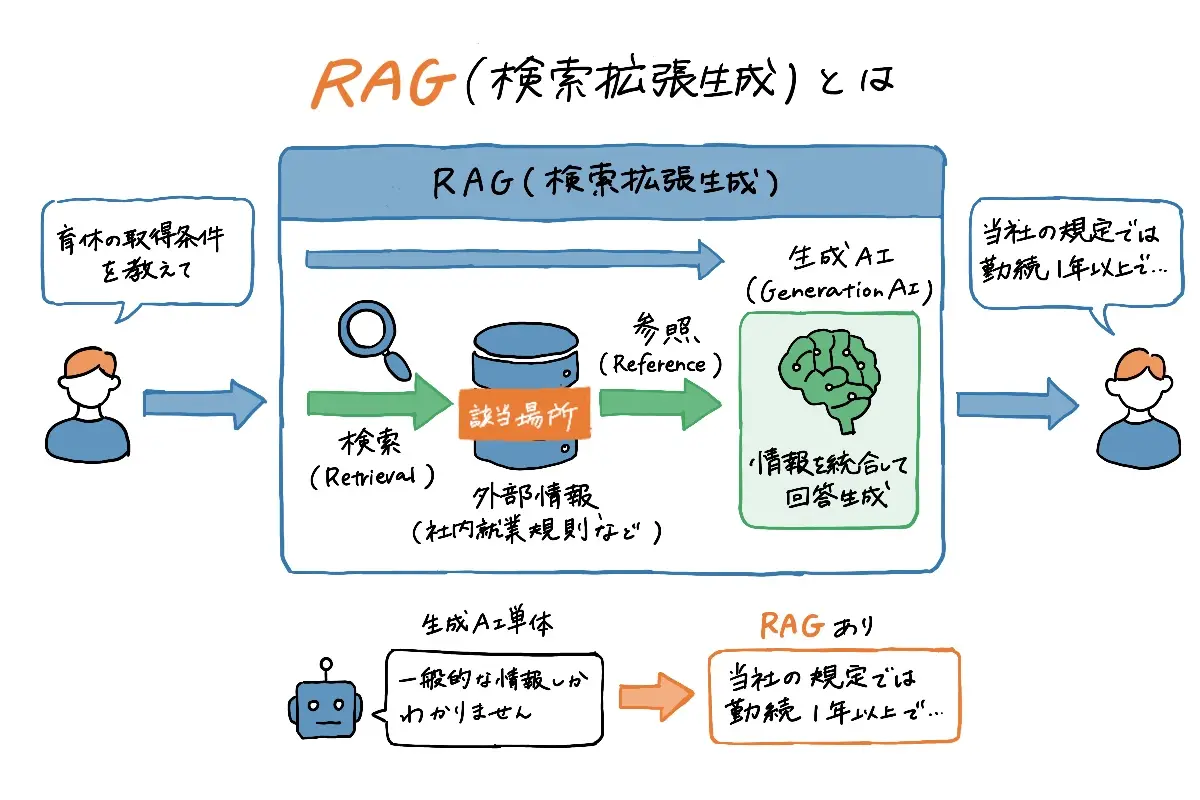
RAG(Retrieval-Augmented Generation)とは、生成AIが外部の情報を検索し、その内容を参照しながら回答を生成する仕組みです。
生成AI単体で回答を完結させるのではなく、「必要な情報を探す工程」を間に挟むことで、回答の正確性や実用性を高めます。たとえば、社員が「育休の取得条件を教えて」と質問した場合、RAGは社内の就業規則から該当箇所を検索し、その内容をもとに回答を生成します。
RAGが注目されている背景
RAGが注目されている理由は明確です。生成AI単体では、社内情報や最新情報を正確に扱えないからです。
ChatGPTなどの生成AIは、学習データに含まれる情報しか参照できません。そのため、社内規程の最新版や、自社独自のFAQ、過去の対応履歴といった情報を扱うことは原理的に不可能です。一方、業務用途では正確性と説明責任が求められます。「AIが言っていたから」では通用しない場面が多くあります。
このギャップを埋める手段として、RAGが広く使われるようになっているのです。
RAGの仕組み
RAGは専門的な用語が多く難しそうに見えますが、やっていることは意外とシンプルです。まずは細かな技術の話は置いておき、どのような流れで動いているのかという全体像から整理します。
RAGの3つのフェーズ
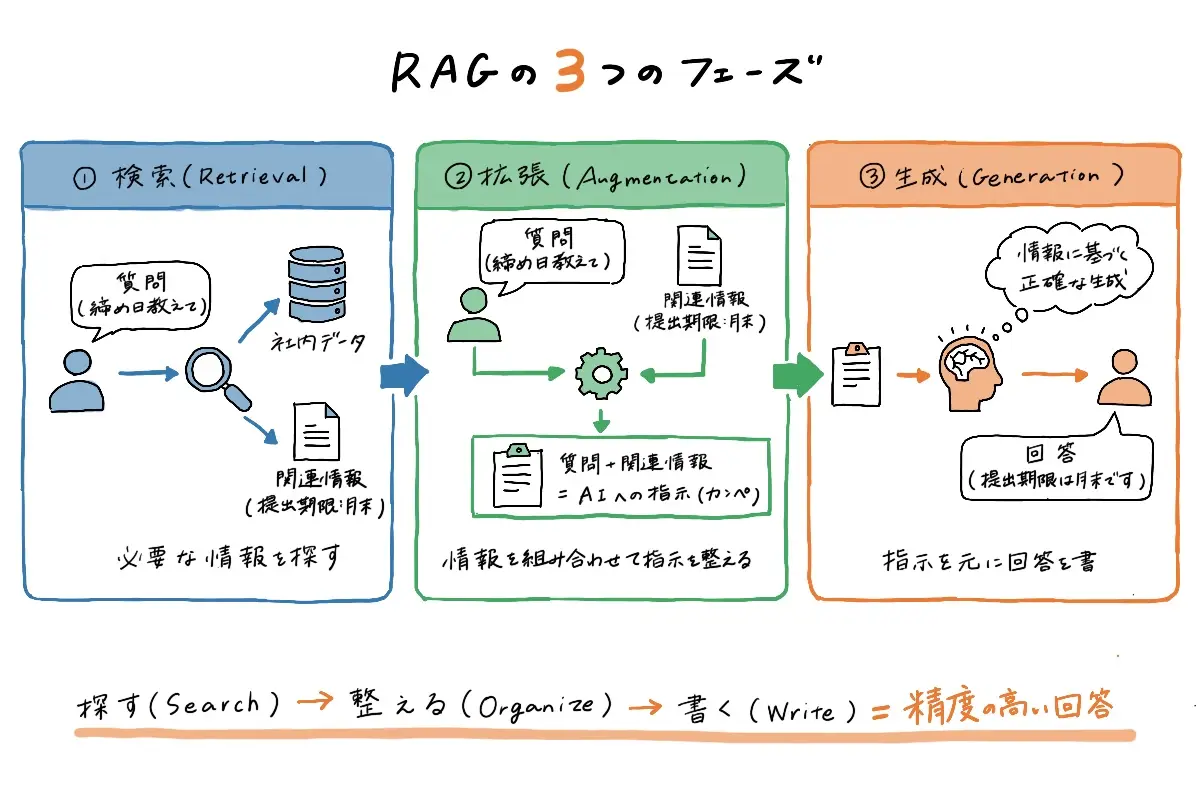
RAGは主に、次の3つのフェーズで構成されています。
①検索(Retrieval)
まず最初に行うのが「検索」です。ユーザーから質問が届くと、社内に蓄積された文書やマニュアル、過去のQ&Aなどの中から、その質問に関係がありそうな情報を探します。
このとき重視されるのは、単語がそのまま一致しているかどうかではありません。質問と文章の「意味が近いかどうか」を基準に、関連性の高い情報を見つけ出します。たとえば、質問に「締め日」と書かれていなくても、「提出期限」や「申請期限」といった表現があれば、同じテーマだと判断して候補に挙げます。
②拡張(Augmentation)
次に行うのが「拡張」です。ここでは、検索で見つかった情報とユーザーの質問を組み合わせ、AIが回答しやすい形に整えます。
単に資料を見つけるだけではなく、「この情報を参考にして答えてください」という形で、質問と参考情報をひとつのセットにしてAIに渡します。いわば、AIにカンペを渡すようなイメージです。
③生成(Generation)
最後が「生成」です。AIは渡された情報を読み取り、それを根拠にしながら自然な文章で回答を作ります。自分の学習知識だけに頼るのではなく、事前に渡された資料を前提にして答えるため、思い込みや事実と異なる内容を作ってしまうリスクを抑えやすくなります。
このように、RAGは「探す」「整える」「書く」という流れを組み込むことで、回答の精度と信頼性を高めている仕組みです。
RAGの成否を決める「検索とデータ設計」
RAGの精度は、最新のAIモデルを使えば自動的に上がる、というものではありません。実際に精度を左右するのは、「どの情報をどう探せる状態にしているか」という検索の仕組みと、その前提となるデータ設計です。
キヤノンITソリューションズのテクニカルレポートでは、RAGの誤回答(Bad評価)の原因を分析した結果、「文書の不備・不足」が46%、「検索精度の低さ」が42%を占めていました。一方で、AIモデル自体の問題は12%にとどまっています。
つまり、多くの誤りはAIが賢くないからではなく、正しい情報を渡せていないから起きているということです。
RAGの成否を分けるポイントは、主に3つあります。
①対象文書の選定
まず重要なのが、どの文書を対象にするかという設計です。社内にあるすべての資料を入れれば良いわけではありません。質問に対して根拠になり得る文書だけを選び、不要な情報を混ぜないことが精度に直結します。
②分割の粒度設計
次に、文書をどの単位で分けるかという設計です。文書はそのまま使うのではなく、一定のかたまりに分割して検索対象にします。この単位が大きすぎると、関係のない情報まで一緒に渡してしまい、小さすぎると前後の文脈が切れて意味が通らなくなります。適切な粒度で分割することが、検索精度を安定させる鍵になります。
③文書の更新・管理
そして、文書の更新と管理です。古いルールと新しいルールが混在していると、AIが誤って古い情報を参照してしまう可能性があります。どの情報が最新版なのかを明確にし、不要な文書を整理することも、RAGの品質を保つうえで欠かせません。
このように、RAGの品質は「モデルの性能」よりも「評価と運用設計」に大きく依存します。
実際の運用では、検索精度やハルシネーション発生率、規程逸脱リスクなどを定量的に可視化し、継続的に改善できる体制が求められます。
当社では、RAG品質評価やレギュレーションチェックを自動化する生成AI品質評価プラットフォーム「GENFLUX」を提供しています。RAGの運用設計まで含めて検討される場合は、あわせてご参照ください。
また、RAGの設計・構築を社内チームで推進したいとお考えの企業様には、AI教育・研修プログラム もご用意しています。LLMの基礎からRAGを含むAIエージェント開発まで、実践的なハンズオンで体系的に学べる講座です。「外部に丸投げではなく、自社で理解して運用したい」という方に最適です。
RAG・ファインチューニング・プロンプト埋め込みの使い分け
ここまでRAGの仕組みを見てきましたが、社内情報を生成AIに扱わせる方法はRAGだけではありません。
目的によっては、別の手法のほうが適しているケースもあります。
そこでここでは、代表的な3つの方法を取り上げ、それぞれがどんな場面に向いているのかを整理します。
まずRAGは、頻繁に更新される大量の社内情報を扱う場合に向いています。
たとえば社内規程、マニュアル、FAQのように情報量が多く、しかも定期的に変わるものです。さらに、「その回答の根拠はどこか」を示したい場合にも適しています。
一方で、社内独自の文体やトーンを覚えさせたいときにはあまり向いていません。
次にファインチューニングは、特定の文体や形式を安定して再現したい場合に向いています。
たとえば、社内レポート特有の書き方や、専門用語の使い方を身につけさせたいときです。ただし、情報が頻繁に変わる場合には不向きです。内容が変わるたびに再学習が必要になるためです。
そして、プロンプトに直接埋め込む方法は、情報量が少なく、あまり変更がない場合に向いています。
簡単なルールや固定的な説明であれば、毎回プロンプトに書き込むだけで十分です。ただし、文書が大量にある場合や、質問ごとに検索が必要なケースには対応しきれません。
RAGを活用した業務イメージ
RAGは「社内情報を参照しながら回答できる」ことが最大の特徴です。
ここでは、社内Wikiや規程などの文書を使う業務を例に、RAGがどう役立つかを具体的に整理します。
社内規程・ルールの参照(人事/総務)
就業規則や稟議ルールなど、社内ルールは頻繁に更新されやすく、誤回答のリスクも高い領域です。「育休は取得できますか?」という質問に対して、古い規程をもとに回答してしまうと実害につながりかねません。
RAGは対象文書を検索して回答するため、根拠となる規程とセットで案内できます。回答に「就業規則第○条に基づき……」といった出典を添えることで、問い合わせを受けた人事担当者の確認工数も削減できます。
業務手順・運用マニュアルの案内(情シス/CS)
「何をどの順番でやるか」が重要な業務では、手順書の参照が必須になります。たとえば「VPN接続がうまくいかない」という問い合わせに対して、RAGが該当する手順書を引き当てて案内できれば、一次問い合わせの自己解決を促せます。
情シスやカスタマーサポートでは、同じ質問が繰り返されることが多く、RAGによる対応標準化の効果が大きい領域です。
FAQ・過去チケットの検索(問い合わせ削減)
似た問い合わせが繰り返される領域では、FAQや過去の対応ログの再利用が効果的です。RAGで「類似ケース」を参照して回答できると、属人化しやすい対応が標準化されます。
また、過去の対応をもとに回答案を提示できるため、経験の浅いメンバーでもスムーズに初動対応がしやすくなります。結果として、教育や確認にかかる負担の軽減にもつながります。
企業におけるRAGの導入事例
ここまで、社内規程やマニュアル参照といった具体的な業務イメージを見てきました。
では実際に、企業ではどのような形でRAGが導入されているのでしょうか。
RAGはすでに実務レベルで活用が始まっており、ナレッジ検索や問い合わせ対応の効率化を中心に導入が進んでいます。ここでは、代表的な活用事例を紹介します。
Uber — RAGを内部ナレッジ検索に活用
Uberは社内のドキュメントやWiki情報を対象にしたRAGパイプラインを構築し、生成AIを活用した社内コーパス検索・回答生成を実現しています。
エンジニアや社内スタッフがナレッジベースに自然言語で問い合わせできる仕組みを整備し、情報検索の効率化を図っています。
引用元:https://www.uber.com/en-JP/blog/enhanced-agentic-rag
JR東日本 — 社内向け生成AIチャットツール活用
JR東日本では、登録した社内文書に基づいて回答を生成するRAGシステムを内製で開発し、2024年10月より全社での試験導入を開始しました。
社内規定やルールなどの文書を対象に、質問に応じて関連情報を検索・回答することで、膨大な社内ナレッジの検索効率化を図っています。
引用元:https://www.jreast.co.jp/press/2024/20240711_ho01.pdf
キヤノンITソリューションズ — 社内検索システムにRAGを導入
キヤノンITソリューションズでは、社内のITシステムや業務フローに関する文書を対象にRAGを導入しました。社員向けサポートセンターの実際の問い合わせ内容をシステムに入力して検証を行い、回答精度の分析結果をテクニカルレポートとして公開しています。
228件の問い合わせを評価した結果、Good評価は全体の約3分の1にとどまり、改善余地が大きいことも正直に報告されています。
引用元:https://www.canon-its.co.jp/column/tech-report/06
SOMPOひまわり生命保険 — RAGをFAQ自動応答に利用
SOMPOひまわり生命保険は、社内のFAQデータベースを対象にしたRAGを用いた生成AIツールを導入しました。
新契約に関する問い合わせを従来の検索+手作業対応から、RAGベースの自動回答に置き換えることで、年間約6,500時間の工数削減を目標としています。
RAG導入のコスト目安
では実際に、RAGを導入するにはどの程度のコストがかかるのでしょうか。
RAGの費用は、対象とする文書量や求める精度、社内にどこまで体制があるかによって大きく変わります。ここでは、一般的な規模を想定した場合の目安を整理します。
初期費用
初期費用の中心となるのは、システム構築と文書整備です。
システム構築費は規模によって差が大きく、簡易的な構成であれば50万円前後から、要件が多い場合は300万円程度まで幅があります。
一方で、見落とされがちなのが文書整備にかかる工数です。RAGは「入っている情報の質」に大きく依存するため、対象文書の選定や整理、重複削除、分割設計などの作業が必要になります。社内工数として1〜3人月程度を見込むケースが一般的です。
また、本格導入前にPoC(検証期間)を設ける企業も多く、2〜3か月程度かけて精度や運用フローを確認します。この期間を通じて、対象範囲や検索設計を調整していくのが一般的です。
運用コスト(月額)
運用フェーズでは、API利用料と保守工数が主なコストになります。API利用料は利用量に応じて変動し、月額1万〜10万円程度がひとつの目安です。
ただし、長期的に重要なのは「文書の更新管理」です。古い情報が残ったままだと、回答精度が下がるリスクがあります。そのため、各部署で文書を随時更新し、検索対象を適切に保つ運用体制が必要になります。
保守運用の工数としては、精度チェックやログ確認、検索条件の調整などを含め、0.5〜1人月程度を見込むケースが一般的です。
RAG導入で失敗しやすいポイント
RAGは導入すれば必ず成功する仕組みではありません。実際に導入した企業からは「期待した精度が出ない」「使われなくなった」という声が少なくありません。ここでは、よくある失敗パターンを原因・具体例・対策まで含めて深掘りします。
失敗パターン1:文書の不備・不足による誤回答
RAGは「検索した文書」をもとに回答を生成します。つまり、参照先の文書に問題があれば、回答も必然的に不正確になります。これは「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」とも表現される、RAGにおける最も根本的な課題です。
たとえば、2019年版と2025年版の就業規則が同じフォルダに混在している場合、検索エンジンが古い方を拾ってしまうことがあります。AIは渡された情報が「古い」とは認識しないため、古い規程を根拠に自信を持って回答してしまいます。
また、文書自体は存在していても、ユーザーが想定外の角度から質問するケースも問題になります。キヤノンITソリューションズの実証では、PC修理フローの文書に「問い合わせ先」や「送付先」は記載されていたものの、「修理から返却までの期間」に関する情報が含まれておらず、回答できなかったケースが報告されています。
失敗パターン2:チャンク設計の失敗による検索精度低下
RAGでは文書をそのまま検索するのではなく、「チャンク」と呼ばれる小さなまとまりに分割してからベクトルデータベースに格納します。この分割の仕方が不適切だと、検索精度が大きく低下します。
チャンクが大きすぎると、1つのチャンクに複数のトピックが混在し、関連性の低い情報まで検索結果に含まれてしまいます。逆にチャンクが小さすぎると、回答に必要な文脈が途切れてしまい、AIに不完全な情報しか渡せません。
たとえば、就業規則の「育児休業」に関する条文が途中で切れて2つのチャンクに分割されてしまった場合、片方だけが検索にヒットし、不完全な情報をもとに回答が生成されることがあります。また、「重要資料.pdf」のような意味のないファイル名や、スキャン画像のみでテキスト情報を持たないPDFは、そもそも検索の対象にすらなりません。
失敗パターン3:ハルシネーションの発生
RAGを導入してもハルシネーションを完全に防ぐことはできません。検索結果が不十分な場合や、複数の文書間で矛盾がある場合、AIは渡された情報を「補完」しようとして、事実と異なる内容を生成することがあります。
質問に関連する文書が見つからなかった場合でも、AIが「何か回答しなければ」と判断して、学習データに基づく一般的な情報で補完してしまうケースがあります。社内規程について質問したのに、一般的な労働法の情報が返ってくるような状況です。ユーザーから見ると「もっともらしい嘘」に見えるため、そのまま信じて業務判断に使ってしまうリスクがあります。
こうしたリスクを防ぐには、RAG応答を定期的にテストし、誤回答率や整合性スコアを可視化しながら改善を回す仕組みが不可欠です。
しかし、これらを人手で継続的に検証するのは現実的ではありません。
そのため近年では、ハルシネーション検知やRAG整合性評価、規程準拠チェックを自動化する仕組みの導入も進んでいます。
具体的な評価設計や自動化の方法については、生成AI品質評価プラットフォームGENFLUXの詳細もご参照ください。
RAGを検討する際のチェックリスト
最後に、RAGが自社に向いているかを判断するための観点を整理します。以下のチェック項目にYESが多い場合、RAGは有力な選択肢です。
まとめ:RAGは生成AIを社内業務に適用するための実装手法である
RAG(検索拡張生成)は、生成AIに社内文書を参照させて回答を生成する仕組みです。ChatGPTなどの生成AI単体では、社内Wiki、規程、業務マニュアルといった自社固有の情報を扱えません。RAGを導入することで、これらの情報を踏まえた正確な回答が可能になり、社内問い合わせ対応や業務手順案内などの実務で活用できます。
ただし、RAGは導入すれば必ず成功する仕組みではありません。文書の品質管理、チャンク設計、権限設計、ハルシネーション対策、運用体制の整備、そして明確な目的設定。これらが揃ってはじめて、RAGは業務で「使える」ツールになります。
検索設計、データ整備、ハルシネーション対策、法令・社内ルールへの準拠確認など、研究と実装の両面からの品質設計が成功の鍵を握ります。
Elithは、AI研究を基盤とした技術力と実社会での実装経験を強みに、RAGの設計から品質評価、運用改善までを一気通貫で支援しています。
「自社にRAGは本当に必要か」「どのユースケースから始めるべきか」といった初期検討段階のご相談も可能です。
Elithが提供する3つの支援:
RAG導入や生成AIの品質設計、社内AI人材の育成についてお悩みの方は、ぜひお気軽にお問い合わせください。

-
 Local LLM2026.06.24ローカルLLMのTCO徹底試算|クラウドAPIと比べて何ヶ月で逆転するか
Local LLM2026.06.24ローカルLLMのTCO徹底試算|クラウドAPIと比べて何ヶ月で逆転するか- LLM
- セキュリティ
- 生成AI活用
-
 AI教育2026.06.17日本 vs 韓国、AIの実力差は?主要AI企業の時価総額・調達額をファクトベースで徹底比較
AI教育2026.06.17日本 vs 韓国、AIの実力差は?主要AI企業の時価総額・調達額をファクトベースで徹底比較- 教育
- 生成AI
-
 AIガバナンス2026.06.16日本版AI法とは?AI事業者ガイドラインと合わせて知るべき国内規制の全体像
AIガバナンス2026.06.16日本版AI法とは?AI事業者ガイドラインと合わせて知るべき国内規制の全体像- AI規制
- 日本版AI法
- AI事業者ガイドライン
-
 2026.06.12FDEとは?AI導入をPoCで終わらせない新しい実装モデルを解説
2026.06.12FDEとは?AI導入をPoCで終わらせない新しい実装モデルを解説 -
 GENFLUX2026.06.05AI活用のボトルネック:AIセーフティとは
GENFLUX2026.06.05AI活用のボトルネック:AIセーフティとは- セーフティ