

ChatGPTでRAGを使う方法|仕組みや実装方法をわかりやすく解説

「ChatGPTは使っているけれど、社内の資料や自社特有の情報には答えてくれない」そんな経験はありませんか?
ChatGPTは非常に便利なツールですが、学習済みのデータをもとに回答するため、自社のマニュアルや最新の社内資料、独自のナレッジには対応できません。「便利なのはわかるけど、うちの業務には使いにくい」と感じている方も多いのではないでしょうか。
そこで注目されているのが「RAG(ラグ)」という技術です。RAGを活用すると、ChatGPTが社内資料や外部データを参照しながら回答できるようになります。専門知識がなくても導入できる方法もあるため、ビジネスの現場でも急速に広がっています。
本記事では、RAGの基本的な仕組みから、ChatGPTへの組み込み方・活用例・導入時の注意点まで、IT知識がなくてもわかるように解説します。「ChatGPTに社内データを学習させるのとは何が違うの?」という疑問にもお答えします。
RAGとは?
RAGとは、Retrieval-Augmented Generationの略称で、「検索して、答える」技術のことです。難しい名前ですが、仕組みはシンプルです。ユーザーの質問に答えるとき、まず関連する資料やデータを検索し、その内容を参照しながら回答を生成する、この2ステップが特徴です。
たとえるなら、「試験を受けるとき、教科書を見ながら答えられる」状態に近いイメージです。暗記(学習済み知識)だけで答えるのではなく、手元の資料を確認してから答えることができます。
通常のChatGPTとの違い
通常のChatGPTは、事前に大量のテキストを学習したデータをもとに回答します。そのため、学習に含まれていない情報については答えられません。
RAGを組み合わせると、回答のたびに外部のデータを参照する仕組みが加わります。ChatGPTが「自社専用の資料棚」を持てるようなイメージで、社内ドキュメントや最新情報を根拠にした回答ができるようになります。
ファインチューニングとの違い
「ChatGPTに社内データを覚えさせたい」と聞いたとき、「ファインチューニング(再学習)」という手法を思い浮かべる方もいるかもしれません。ファインチューニングとは、AIモデル自体を追加学習させる技術で、特定の文体やトーンに合わせたい場合などに使われます。
一方RAGは、モデルには手を加えず、「回答時に参照するデータを渡す」アプローチです。更新頻度の高い社内資料や、根拠の透明性が求められる用途ではRAGが適しています。どちらが優れているというわけではなく、目的に応じた使い分けが重要です。
関連記事:『RAG(検索拡張生成)とは?社内Wiki・規程を生成AIで使うための仕組みと実例』
ChatGPTでRAGを使うと何が変わる?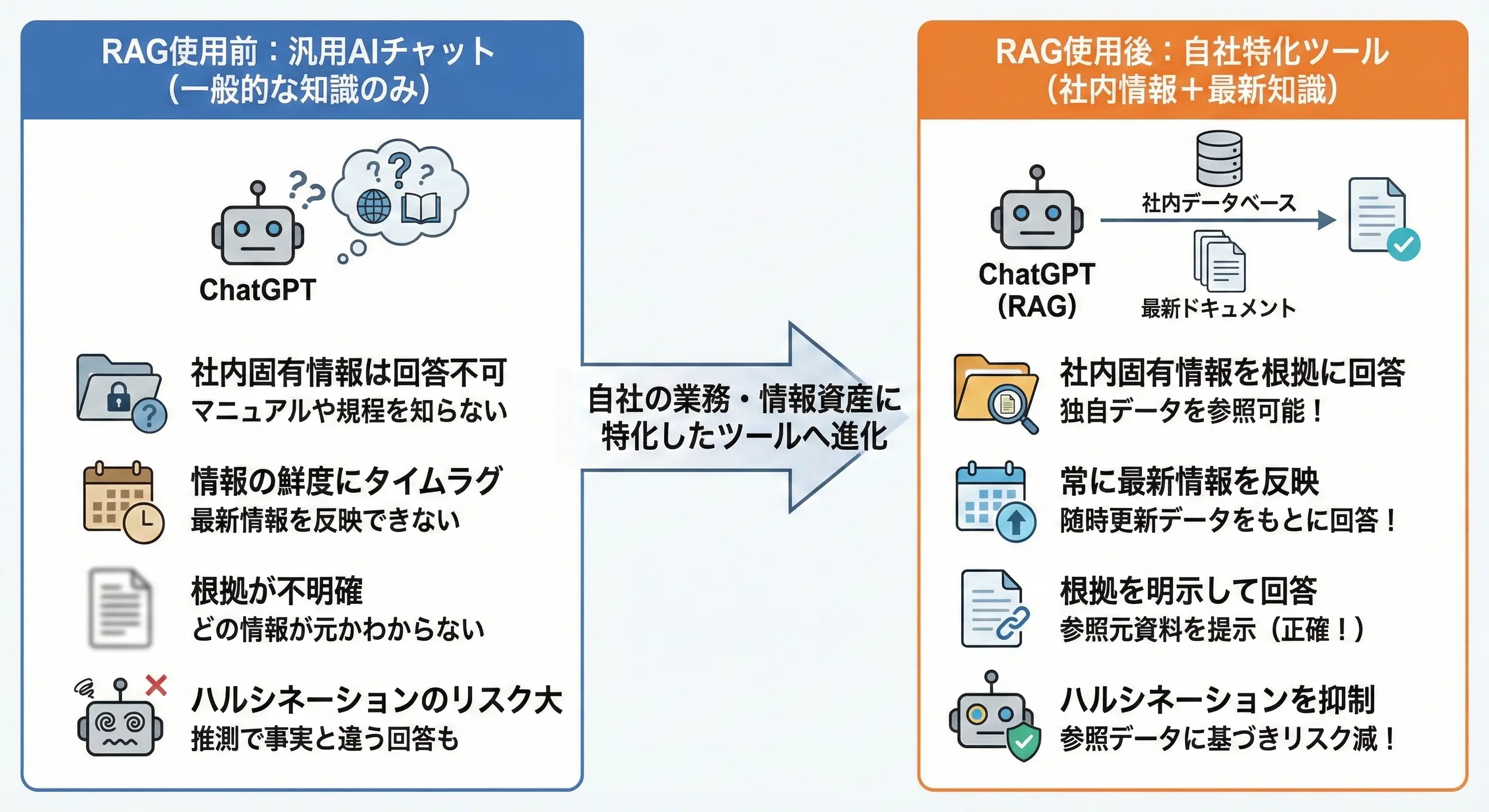
「RAGを使う前」と「使った後」では、ChatGPTの使い勝手がどう変わるのでしょうか。業務での活用イメージとあわせて確認しましょう。
まず大きく変わるのが、社内固有の情報を回答に使えるようになる点です。通常のChatGPTは自社のマニュアルや議事録、社内規程といったデータを学習していないため、これらに関する質問には答えられません。RAGを組み合わせることで、こうした独自情報を根拠にした回答が可能になります。
また、情報の鮮度も改善します。ChatGPTの学習データには更新のタイムラグがあり、最新の情報を反映するのが苦手です。RAGであれば参照するデータを随時更新できるため、常に最新のドキュメントをもとに回答させることができます。
さらに、「この回答はどの資料をもとにしているか」を明示した設計もしやすくなります。根拠を提示しながら回答できるため、正確性が求められる業務での活用にも適しています。
加えて、ハルシネーション(AIが事実と異なる内容を生成してしまう現象)を抑える効果もあります。参照すべきデータを明示的に渡すことで、ChatGPTが不足分を推測で補完してしまうリスクが減ります。
「汎用AIチャット」だったChatGPTを、自社の業務・情報資産に特化したツールへと育てられるのが、RAGの最大の価値です。
ChatGPT RAGの仕組み
RAGを使うと、ChatGPTの裏側ではどのようなことが起きているのでしょうか。実際に操作するのはチャット画面だけですが、質問が送信されてから回答が返ってくるまでの間に、4つの処理が自動で行われています。
難しい技術の話ではなく、「何が起きているか」のイメージをつかむために確認しておきましょう。
① データを用意する
まず、ChatGPTに参照させたいデータを用意します。社内マニュアル・FAQ・議事録・製品カタログなど、テキストとして読み取れるものであれば幅広く対応できます。
ここで用意するデータの鮮度と正確さが、後の回答品質に直結します。「ゴミを入れればゴミが出てくる」という原則は、RAGでも変わりません。
② データをベクトル化する
用意した文書を、コンピューターが「意味」で検索できる形式(ベクトルと呼ばれる数値データ)に変換します。通常の検索と違い、「完全一致する言葉」がなくても意味が近い文書を見つけられるのが特長です。
変換されたデータは「ベクトルデータベース」と呼ばれる専用の保管場所に格納されます。この変換・格納作業は基本的に初回に一括で行い、その後はドキュメントの追加・更新のたびに再実行が必要です。運用設計の段階で更新フローを組み込むことが不可欠です
③ ユーザーの質問に関連するデータを検索する
ユーザーが質問を入力すると、その質問も同じ方法でベクトルに変換されます。そして、データベースの中から「意味的に近い文書」を自動で探し出します。
たとえば「有給の申請方法を教えて」と質問したとき、「年次休暇の取得手続きについて」と書かれた資料も検索対象に引っかかります。
キーワードが完全に一致しなくても関連情報を拾える点が、通常の検索より優れています。
④ 検索結果をプロンプトに含めてChatGPTに渡し、回答を生成する
検索で見つかった関連文書を、ユーザーの質問とセットでChatGPTに渡します。ChatGPTはその資料を「読んだうえで」回答を生成するため、社内データに基づいた精度の高い回答が返ってきます。
また、「提供された資料に書かれていない場合は、わからないと答えてください」という指示をあわせて設定することで、ChatGPTが推測で誤った回答をするリスクをさらに抑えられます。
ChatGPTでRAGを使う方法
RAGの導入方法は一つではありません。開発不要で今すぐ使えるものから、自社仕様に作り込むものまで、規模や目的に応じた3つのアプローチを紹介します。
方法① ChatGPT Enterprise
ChatGPT Enterprise(およびTeam)では、「Custom GPTs」の機能を使うことでRAGに近い仕組みを構築できます。GPTの作成画面でPDFや社内ドキュメントを「Knowledge」として登録すると、ユーザーの質問に対して関連する箇所を自動で検索・参照しながら回答を生成します。内部的にはベクトル検索が行われており、仕組みとしてはRAGと同様の処理です。また、Enterpriseプランでは Google Drive や SharePoint などの外部データソースとの連携機能も用意されており、既存の社内ストレージをそのまま参照先として活用することも可能です。
いずれも専門的な開発は不要で、導入ハードルが低い点が魅力です。一方、チャンク分割の細かい調整や検索ロジックのカスタマイズには対応していないため、「まず試してみたい」「小規模で使えれば十分」という段階に適しています。
参照元:https://chatgpt.com/ja-JP/business/enterprise/
方法② OpenAI APIで構築
 柔軟性を重視するなら、OpenAI APIを使ったシステム構築が選択肢になります。エンジニアが関与する前提ですが、自社の業務フローや既存システムに合わせた設計が可能です。大まかな構築ステップは次のとおりです。
柔軟性を重視するなら、OpenAI APIを使ったシステム構築が選択肢になります。エンジニアが関与する前提ですが、自社の業務フローや既存システムに合わせた設計が可能です。大まかな構築ステップは次のとおりです。
・OpenAIのAPIキーを取得し、接続準備をする
・社内ドキュメントをベクトルデータに変換する(Embedding API を使用)
・変換したデータをベクトルデータベースに格納する
・ユーザーの質問に関連するデータを検索する仕組みを実装する
・検索結果と質問をセットでChatGPTに渡し、回答を生成する
この方法は、UI設計からセキュリティ対策まで自由にカスタマイズできます。ただし、構築・運用にはエンジニアリングのリソースが必要な点は留意が必要です。
参照元:https://openai.com/ja-JP/api/
方法③ ノーコードツール
「開発はできないけれど、自社仕様に近いものを作りたい」という場合は、ノーコード・ローコードのRAGツールが有力な選択肢です。DifyやFlowise、LlamaIndexベースのサービスなど、GUI操作でデータ登録からチャットボット構築まで完結できるツールが増えています。
開発不要で導入スピードが速く、まずPoCとして試しやすい点が強みです。一方、独自の業務フローへの細かい対応や、既存システムとの深い連携においては、API構築と比べて制約が生じることもあります。コストと柔軟性のバランスで判断しましょう。
ChatGPT × RAGの活用例
RAGはどのような業務課題に応えられるのでしょうか。現場での活用イメージが湧きやすいよう、代表的な5つのシーンを紹介します。
社内ナレッジ検索
「あの件の決定事項、どこに書いてあったっけ?」会議の議事録や社内Wikiをいちいち探す手間は、多くの職場で発生しています。RAGを活用すれば、蓄積された議事録や社内資料を自然な言葉で検索し、即座に回答を引き出せます。特定の担当者しか知らない暗黙知の共有にも効果的です。
FAQチャットボット
「同じ質問が何度も来て担当者の負担が大きい」という問い合わせ業務の課題に対して、RAGベースのチャットボットは有効な解決策になります。既存のFAQデータや問い合わせ履歴を登録するだけで、自動応答できる範囲が広がります。人が対応すべき案件の絞り込みにもつながります。
契約書・法務文書の検索
大量の契約書から特定の条項を探す作業は、時間もかかり見落としリスクも伴います。RAGを活用することで、「解約に関する条件が記載されている箇所はどこか」といった質問に対して、関連する契約書の箇所を横断的に提示することが可能です。最終的な法的判断は専門家が行う前提ですが、確認作業の大幅な時間短縮が期待できます。
業務マニュアル検索
厚いマニュアルを最初から読むのではなく、「この手順を知りたい」という質問に対して該当箇所を即座に返せるのがRAGの強みです。新人研修での活用や、現場スタッフが作業中にその場で確認する用途にも向いています。マニュアルの内容が更新されても、データを差し替えるだけで回答内容も追随します。
カスタマーサポート
製品仕様のドキュメントや過去の問い合わせ対応履歴をRAGに組み込めば、サポートスタッフの経験年数に関わらず一定水準の回答品質を保てます。対応品質のばらつきを抑え、顧客満足度の安定化につながる活用例です。
RAGの活用シーンを自社の業務に落とし込み、企画・提案できるスキルを身につけたい方には、Elithの「生成AI活用講座」もご活用いただけます。エンジニアではなくても、RAGを実務への応用することが可能になります。
ChatGPT RAGの注意点
RAGは業務効率化に有効な技術ですが、導入前に知っておくべき注意点もあります。「思ったより使えない」とならないよう、あらかじめ確認しておきましょう。
データの品質が回答精度を左右する
RAGの回答品質は、登録するデータの質に大きく依存します。古い情報や内容に矛盾のあるドキュメントが混在していると、それをもとにした誤った回答が返ってくる場合があります。
「精度が上がらない」と感じたとき、原因の多くはデータ側にあります。定期的な更新・整理の仕組みを、導入設計の段階から組み込むことが重要です。
ハルシネーションが完全にはなくならない
RAGによってハルシネーション(AIが事実と異なる内容を生成してしまう現象)は抑えられますが、ゼロにはなりません。検索で十分な関連データが見つからなかったとき、ChatGPTが不足分を補完しようとして誤情報を返すケースが残ります。
「資料に記載がない場合は回答しない」という設定をあわせて行うことで、リスクを最小化できます。
チャンク分割の設計が重要
RAGでは、ドキュメントをある程度の長さの「かたまり(チャンク)」に分割してから登録します。この分割のサイズが検索精度に影響するため、設計が重要です。
細かく切りすぎると文脈が失われ、大きすぎると不要な情報が混入します。ノーコードツールではある程度自動で処理してくれますが、API構築の場合は専門家の知見が役立つポイントです。
セキュリティ・アクセス制御
社内の機密情報をRAGに組み込む場合、「誰がどのデータにアクセスできるか」の権限設計が欠かせません。
たとえば人事情報が全社員から参照できる状態になるのは避けなければなりません。クラウドサービスを利用する場合は、データの保管場所や利用規約も事前に確認しておきましょう。
コストと運用
RAGの運用にはランニングコストが伴います。データの保管費用、AIへの問い合わせ費用、システムの保守管理など、スケールに応じてコストは変動します。
最初から大規模に展開しようとせず、小さな用途でPoCを行い、効果を確認しながら段階的に広げていくアプローチが現実的です。
まとめ
RAGは、ChatGPTを単なる対話ツールから「業務で使える知識基盤」へと拡張する技術です。ただし重要なのは、技術そのものよりも、どのデータを使い、どの業務に適用し、どのように評価・改善していくかという設計の部分にあります。
小規模なPoCから始め、データ品質の維持と検証サイクルを回しながら段階的に展開することが、RAG導入を成功させる現実的なアプローチです。
もし、自社の業務に当てはめたときの設計整理や技術選定に迷いがある場合は、Elithへの相談も一つの選択肢です。RAG構築の技術支援に加え、経営・企画層向けの「AIエグゼクティブ講座」では、AI導入の意思決定に必要な知識を体系的に学べます。

-
 Local LLM2026.06.24ローカルLLMのTCO徹底試算|クラウドAPIと比べて何ヶ月で逆転するか
Local LLM2026.06.24ローカルLLMのTCO徹底試算|クラウドAPIと比べて何ヶ月で逆転するか- LLM
- セキュリティ
- 生成AI活用
-
 AI教育2026.06.17日本 vs 韓国、AIの実力差は?主要AI企業の時価総額・調達額をファクトベースで徹底比較
AI教育2026.06.17日本 vs 韓国、AIの実力差は?主要AI企業の時価総額・調達額をファクトベースで徹底比較- 教育
- 生成AI
-
 AIガバナンス2026.06.16日本版AI法とは?AI事業者ガイドラインと合わせて知るべき国内規制の全体像
AIガバナンス2026.06.16日本版AI法とは?AI事業者ガイドラインと合わせて知るべき国内規制の全体像- AI規制
- 日本版AI法
- AI事業者ガイドライン
-
 2026.06.12FDEとは?AI導入をPoCで終わらせない新しい実装モデルを解説
2026.06.12FDEとは?AI導入をPoCで終わらせない新しい実装モデルを解説 -
 GENFLUX2026.06.05AI活用のボトルネック:AIセーフティとは
GENFLUX2026.06.05AI活用のボトルネック:AIセーフティとは- セーフティ
